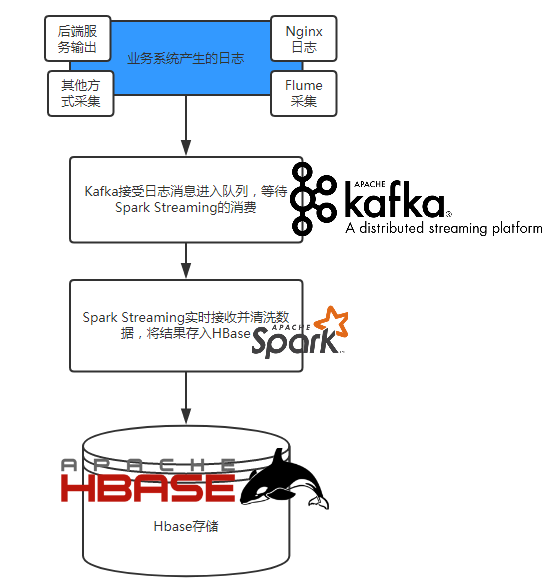
随着公司业务发展,对大数据的获取和实时处理的要求就会越来越高,日志处理、用户行为分析、场景业务分析等等,传统的写日志方式根本满足不了业务的实时处理需求,所以本人准备开始着手改造原系统中的数据处理方式,重新搭建一个实时流处理平台,主要是基于Hadoop生态,利用Kafka作为中转,SparkStreaming框架实时获取数据并清洗,将结果多维度的存储进HBase数据库。
整个平台大致的框架如下:
操作系统:Centos7
用到的框架:
1. Flume1.8.0
2. Hadoop2.9.0
3. kafka2.11-1.0.0
4. Spark2.2.1
5. HBase1.2.6
6. ZooKeeper3.4.11
7. maven3.5.2
整体的开发环境是基于JDK1.8以上以及Scala,所以得提前把java和Scala的环境给准备好,接下来就开始着手搭建基础平台:
一、配置开发环境
下载并解压JDK1.8,、下载并解压Scala,配置profile文件:
vim /etc/profile
1 | export JAVA_HOME=/usr/java/jdk1.8.0_144 |
source /etc/profile
二、配置zookeeper、maven环境
下载并解压zookeeper以及maven并配置profile文件
wget http://mirrors.hust.edu.cn/apache/maven/maven-3/3.5.2/binaries/apache-maven-3.5.2-bin.tar.gz
tar -zxvf apache-maven-3.5.2-bin.tar.gz -C /usr/local
wget http://mirrors.hust.edu.cn/apache/zookeeper/zookeeper-3.4.11/zookeeper-3.4.11.tar.gz
tar -zxvf zookeeper-3.4.11.tar.gz -C /usr/local
vim /etc/profile
1 | export MAVEN_HOME=/usr/local/apache-maven-3.5.2 |
source /etc/profile
zookeeper的配置文件配置一下:
cp /usr/local/zookeeper-3.4.11/conf/zoo_sample.cfg /usr/local/zookeeper-3.4.11/conf/zoo.cfg
然后配置一下zoo.cfg里面的相关配置,指定一下dataDir目录等等
启动zookeeper:
/usr/local/zookeeper-3.4.11/bin/zkServer.sh start
如果不报错,jps看一下是否启动成功
三、安装配置Hadoop
Hadoop的安装配置在之前文章中有说过(传送门),为了下面的步骤方便理解,这里只做一个单机版的简单配置说明:
下载hadoop解压并配置环境:
wget http://mirrors.hust.edu.cn/apache/hadoop/common/hadoop-2.9.0/hadoop-2.9.0.tar.gz
tar -zxvf hadoop-2.9.0.tar.gz -C /usr/local
vim /etc/profile
1 | export HADOOP_HOME=/usr/local/hadoop-2.9.0 |
source /etc/profile
配置hadoop 进入/usr/local/hadoop-2.9.0/etc/hadoop目录
cd /usr/local/hadoop-2.9.0/etc/hadoop
首先配置hadoop-env.sh、yarn-env.sh,修改JAVA_HOME到指定的JDK安装目录/usr/local/java/jdk1.8.0_144
创建hadoop的工作目录
mkdir /opt/data/hadoop
编辑core-site.xml、hdfs-site.xml、yarn-site.xml等相关配置文件,具体配置不再阐述请看前面的文章,配置完成之后记得执行hadoop namenode -format,否则hdfs启动会报错,启动完成后不出问题浏览器访问50070端口会看到hadoop的页面。
四、安装配置kafka
还是一样,先下载kafka,然后配置:
wget http://mirrors.hust.edu.cn/apache/kafka/1.0.0/kafka_2.11-1.0.0.tgz
tar -zxvf kafka_2.11-1.0.0.tgz -C /usr/local
vim /etc/profile
1 | export KAFKA_HOME=/usr/local/kafka_2.11-1.0.0 |
source /etc/profile
进入kafka的config目录,配置server.properties,指定log.dirs和zookeeper.connect参数;配置zookeeper.properties文件中zookeeper的dataDir,配置完成后启动kafka
kafka-server-start.sh -daemon $KAFKA_HOME/config/server.properties
可以用jps查看有没有kafka进程,然后测试一下kafka是否能够正常收发消息,开两个终端,一个用来做producer发消息一个用来做consumer收消息,首先,先创建一个topic
kafka-topics.sh --create --zookeeper 127.0.0.1:2181 --replication-factor 1 --partitions 1 --topic testTopic
kafka-topics.sh --describe --zookeeper localhost:2181 --topic testTopic
如果不出一下会看到如下输出:1
2Topic:testTopic PartitionCount:1 ReplicationFactor:1 Configs:
Topic: testTopic Partition: 0 Leader: 0 Replicas: 0 Isr: 0
然后在第一个终端中输入命令:
kafka-console-producer.sh –broker-list localhost:9092 –topic testTopic
在第二个终端中输入命令:
kafka-console-consumer.sh –zookeeper 127.0.0.1:2181 –topic testTopic
如果启动都正常,那么这两个终端将进入阻塞监听状态,在第一个终端中输入任何消息第二个终端都将会接收到。
五、安装配置HBase
下载并解压HBase:
wget http://mirrors.hust.edu.cn/apache/hbase/1.2.6/hbase-1.2.6-bin.tar.gz
tar -zxvf hbase-1.2.6-bin.tar.gz -C /usr/local/
vim /etc/profile
1 | export HBASE_HOME=/usr/local/hbase-1.2.6 |
source /etc/profile
修改hbase下的配置文件,首先修改hbase-env.sh,主要修改JAVA_HOME以及相关参数,这里要说明一下HBASE_MANAGES_ZK这个参数,因为采用了自己的zookeeper,所以这里设置为false,否则hbase会自己启动一个zookeeper
cd /usr/local/hbase-1.2.6/conf
vim hbase-env.sh
1 | export JAVA_HOME=/usr/local/java/jdk1.8.0_144/ |
然后修改hbase-site.xml,我们设置hbase的文件放在hdfs中,所以要设置hdfs地址,其中tsk1是我安装hadoop的机器的hostname,hbase.zookeeper.quorum参数是安装zookeeper的地址,这里的各种地址最好用机器名
vim hbase-site.xml
1 | <configuration> |
配置完成后启动hbase,输入命令:
start-hbase.sh
完成后查看日志没有报错的话测试一下hbase,用hbase shell进行测试:
hbase shell
hbase(main):001:0>create 'myTestTable','info'
0 row(s) in 2.2460 seconds
=> Hbase::Table - myTestTable
hbase(main):003:0>list
TABLE
testTable
1 row(s) in 0.1530 seconds
=> ["myTestTable"]
至此,hbase搭建成功,访问以下hadoop的页面,查看file system(菜单栏Utilities->Browse the file system),这时可以看见base的相关文件已经载hadoop的文件系统中。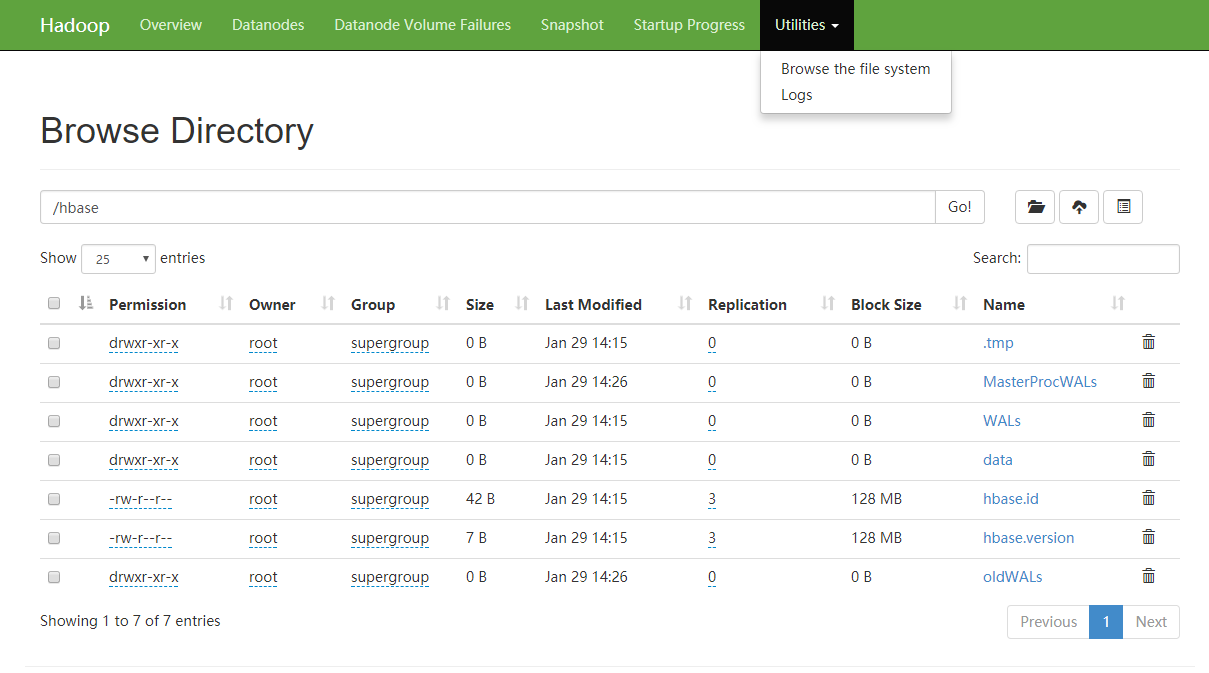
六、安装spark
下载spark并解压
wget http://mirrors.hust.edu.cn/apache/spark/spark-2.2.1/spark-2.2.1-bin-hadoop2.7.tgz
tar -zxvf spark-2.2.1-bin-hadoop2.7.tgz -C /usr/local
vim /etc/profile
1 | export SPARK_HOME=/usr/local/spark-2.2.1-bin-hadoop2.7 |
source /etc/profile
七、测试
至此,环境基本搭建完成,以上搭建的环境仅是服务器生产环境的一部分,涉及服务器信息、具体调优信息以及集群的搭建就不写在这里了,下面我们写一段代码整体测试一下从kafka生产消息到spark streaming接收到,然后处理消息并写入HBase。先写一个HBase的连接类HBaseHelper:
1 | public class HBaseHelper { |
再写一个测试类KafkaRecHbase用来做spark-submit提交
1 | package com.test.spark.spark_test; |
编译提交到服务器,执行命令:
spark-submit --jars $(echo /usr/local/hbase-1.2.6/lib/*.jar | tr ' ' ',') --class com.test.spark.spark_test.KafkaRecHbase --packages org.apache.spark:spark-streaming-kafka-0-8_2.11:2.2.1 /opt/FileTemp/streaming/spark-test-0.1.1.jar tsk1:2181 test testTopic 1
没报错的话执行kafka的producer,输入几行数据在HBase内就能看到结果了!
八、装一个Flume实时采集Nginx日志写入Kafka
Flume是一个用来日志采集的框架,安装和配置都比较简单,可以支持多个数据源和输出,具体可以参考Flume的文档,写的比较全传送门
下载Flume并配置环境
wget http://mirrors.hust.edu.cn/apache/flume/1.8.0/apache-flume-1.8.0-bin.tar.gz
tar -zxvf apache-flume-1.8.0-bin.tar.gz -C /usr/local
vim /etc/profile
1 | export FLUME_HOME=/usr/local/apache-flume-1.8.0-bin/ |
source /etc/profile
写一个Flume的配置文件在flume的conf目录下:
vim nginxStreamingKafka.conf
1 | agent1.sources=r1 |
kafka创建一个名为flumeKafka的topic用来接收,然后启动flume:
flume-ng agent --name agent1 --conf $FLUME_HOME/conf --conf-file $FLUME_HOME/conf/nginxStreamingKafka.conf -Dflume.root.logger=INFO,console
如果没有报错,Flume将开始采集opt/data/nginxLog/nginxLog.log中产生的日志并实时推送给kafka,再按照上面方法写一个spark streaming的处理类进行相应的处理就好。
OK!全部搞定,然而~~~~就这样就搞定了?NO!!!这只是万里长征的第一步!呵呵!